
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 3dmapping
- Ros
- sensorfusion
- 3dgaussiansplatting
- LIDAR
- differentiablerendering
- opencv
- gaussiansplatting
- pointcloud
- turtlebot
- rospackages
- roslaunch
- ComputerVision
- raspberrypi
- Slam
- imageprocessing
- usbcamera
- vectorfields
- catkinworkspace
- rosnoetic
- realtimerendering
- turtlebot3
- tilebasedrasterizer
- electromagnetism
- adaptivedensitycontrol
- rostopics
- vectorcalculus
- alphablending
- covariancematrix
- NERF
- Today
- Total
Wiredwisdom
LeNet-5 (1998) 본문

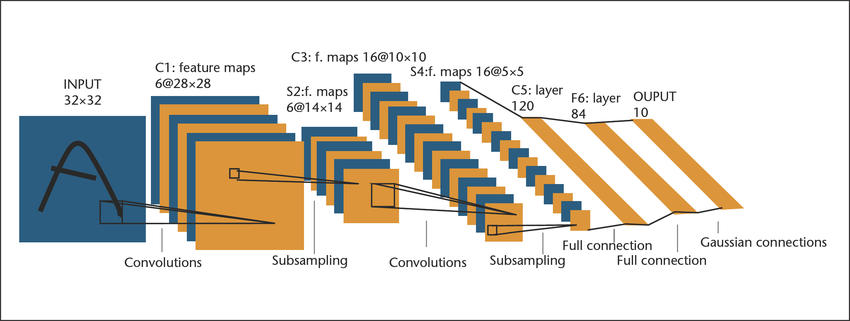
각 레이어 설명
1. convolutions : 일반적인 CNN 과정이다. 처음에는 6개의 커널을 사용하여 `28xx28`사이즈의 출력값을 6개 생성한다.
2. subsampling : 훗날에 나오는 Pooling 중에서도 Average Pooling을 선현변환 시킨 것이 Subsampling이 된다.
`text(avg)=1/(nxxn) Sigma_(i=1)^(nxxn) *x_i`
`y_j=betaj*text(avg)+b_j`
`f(y_j)=text(Activate Function)(y_j)`
여기서는 `14xx14` 커널을 6개 사용하여 6개의 출력을 했다.
당연하게도 각 입력층은 각각의 subsampling 을 하여 cnn과 다르게 합산되지 않고 개별 출력결과를 가진다.
따라서 입력과 출력의 갯수는 동일하다.
차원의 변화는 해상도가 유일하다.
3. convolutions : 16개의 커널로 `10xx10` 의 16개의 출력을 만든다.
4. subsampling : `5xx5`로 해상도를 축소한다.
5. Full connection : 여기서 각 이미지의 배열을 선형화 시켜 concatenate를 한다.
출력 노드는 120으로 지정된다.
6. Full connection : 두번재 FCL 를 통해 84개의 출력으로 전환한다.(84개의 노드 in Layer)
7. Gaussian connections : 학습된 출력 값과의 유사도를 판정한다.

현재 우리가 접하는 신경망은 벡터 내적(dot product)을 통해 유사도를 계산하고 이 값들을 Softmax를 통해 가장 유사도가 큰 값을 토대로 판정하는 방식을 사용한다. 하지만 Gaussian Connections의 경우 RBF, 즉 Radial Basis Function 의 경우는 벡터스토어에서 유사도가 높은 값을 `L_2`로 distance가 최소가 되는 값을 찾는 것처럼 이미 지정되어 있는 정답의 값들(여기서는 각 클래스마다 84개의 배열이 되겠다)과의 거리를 비교하여 최소가 되는 값을 정답으로 간주한다는 것이다.
물론 클래스에 해당되는 84개의 파라미터는 역전파를 통해 학습이 된다. 그러나 softmax 사용하지 않기 때문에 좀 더 특별한 손실함수를 사용한다. 요점은 정답은 더 거리가 좁아지도록 학습하고 그 이외의 클래스와는 distance가 벌어지도록 학습한다는 것이다.
'2D Vision > CNN (Object Detection)' 카테고리의 다른 글
| Layer Normalization (0) | 2025.06.27 |
|---|---|
| Alexnet Architecture (2012) (0) | 2025.06.27 |
| Depthwise Convolution (0) | 2025.04.07 |


