
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- electromagnetism
- imageprocessing
- pointcloud
- vectorcalculus
- rostopics
- opencv
- LIDAR
- differentiablerendering
- raspberrypi
- roslaunch
- Slam
- turtlebot
- tilebasedrasterizer
- NERF
- vectorfields
- rospackages
- rosnoetic
- covariancematrix
- Ros
- realtimerendering
- alphablending
- usbcamera
- ComputerVision
- 3dmapping
- turtlebot3
- 3dgaussiansplatting
- gaussiansplatting
- adaptivedensitycontrol
- sensorfusion
- catkinworkspace
- Today
- Total
Wiredwisdom
NeRF summary 본문
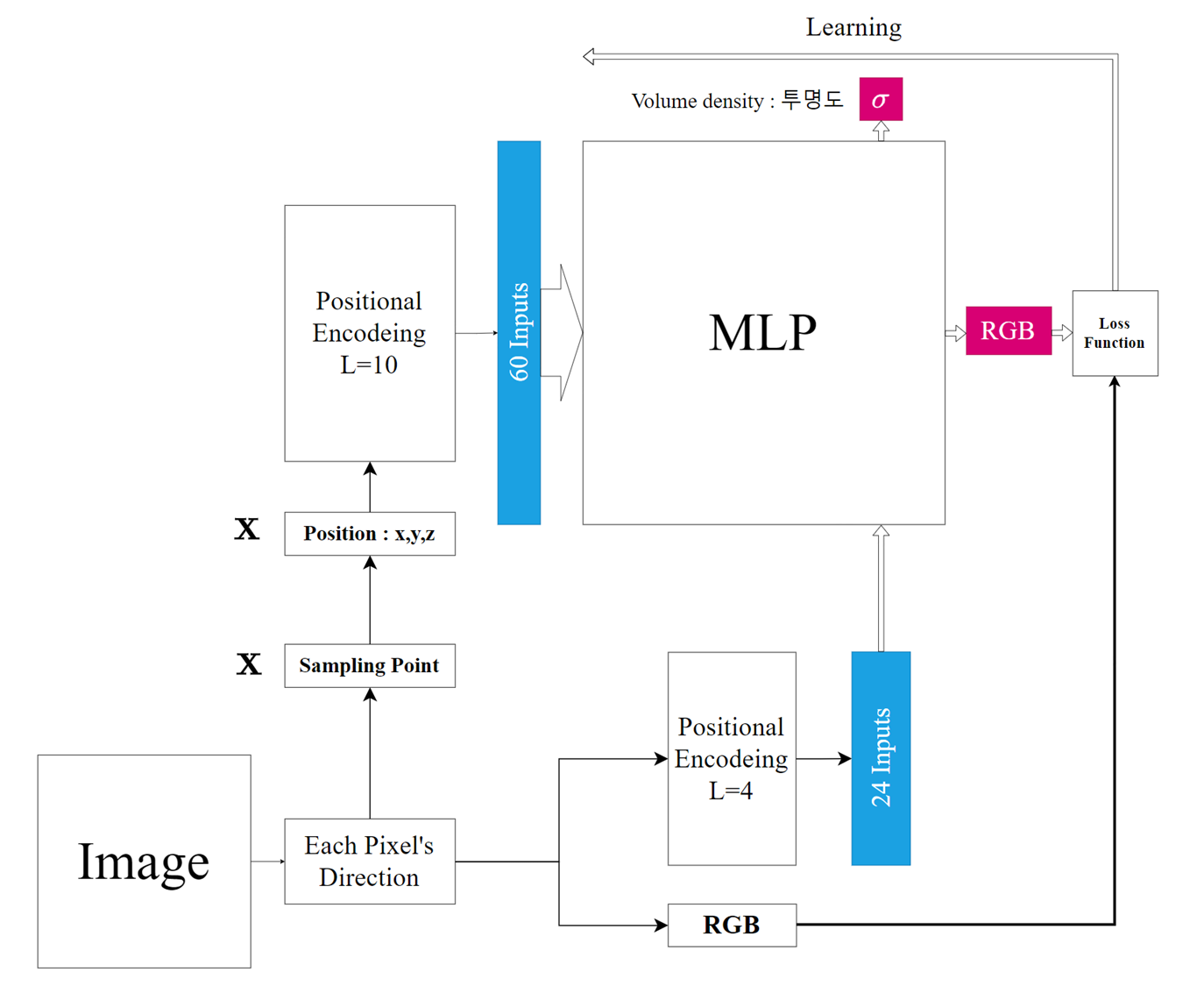
시스템의 알고리즘을 보자면 다음과 같다. 먼저 초기 인풋이 샘플링 하고자 하는 3차원 좌표값을 Positional Encoding을 하여 60개의 인풋으로 치환하여 입력하고, 후반기의 신경망에 추가로 해당 샘플링된 좌표의 View Direction 을 입력한다.
그렇게 나오는 최종 색상 값과 실제 색상 값의 차이를 Loss Function으로 하여 신경망을 학습시키는 과정으로 이루어진다.
그렇기 때문에 사진한장을 학습시키기 위해서는 row와 column 간의 모든 픽셀 숫자 만큼 신경망을 백프로파게이션 하여 학습을 시키고, 다음 이미지로 넘어가는 방식으로 이루어지는 것이다.


초기 이미지에서 각 픽셀에 따른 Ray에 샘플링 된 수 많은 좌표값들이 다른 이미지에서 특정 픽셀의 Ray에 의해 근접하여 교정되는 과정들이 수반된다. 정확하게 좌표가 겹치는 일은 거의 일어나지 않지만, 가장 가까운 부분에서 샘플링 된 데이터를 기반으로 특정 포인트와 특정 방향의 색상과 밀도가 출력되게 되는 것이다.
때문에 여기서의 신경망은 거대한 비선형 방정식들의 모든 데이터를 가지고 있다고 봐도 무방할지도 모르겠으며
모든 포인트를 학습시키지 않고 실수값의 좌표들을 학습시키는 것 만으로 해상도를 충분히 높여도 높은 디테일의 Novel View가 출력되는 것이다.

특정 이미지에서 특정 픽셀에 대한 Ray가 뚫고 들어가는 대상에서의 샘플링된 좌표들의 모습이다.
정리해보자.
기억해야 하는 가장 중요한 부분은, 하나의 이미지에서 하나의 특정 픽셀에 투영되는 Ray는
3D Modeling을 이행하는 공간에서 특정 알고리즘으로 샘플링되는 실수값의 3차원 좌표값들을 토대로 학습이 진행이 되고
학습이 종료 된 이후에는, Inference 상태에서도 Novel View에 대한 이미지의 Ray들에 대하여도
각각의 픽셀에 상응하는 Ray를 다시 투과하면서 샘플링되는 포인트들의 이산적인 축척이 되는데
여기서 물체의 밀도가 한계점에 이르르면(Max가 되면) 이후의 샘플링 포인트의 색상과 밀도에 대한 Accumulation은 중단된다는 것이다.
따라서 하나의 이미지를 생산하는데에는
이미지의 해상도, 그리고 각 Ray들의 최대 밀도 축적 까지의 샘플링 횟수만큼 Inference가 되는 것이다.
고로, 높은 해상도의 이미지를 출력할수록 엄청난 량의 연산들이 이행되어야 하며, 그 이유는 모델링이 되는 공간에서의 각 포인트들이 가지는 색상과 밀도의 관계는 연속적이면서도 비선형성을 가지는 함수관계를 갖기 때문에 굉장히 정밀하면서도 매우 무거운 신경망이기 때문이다.
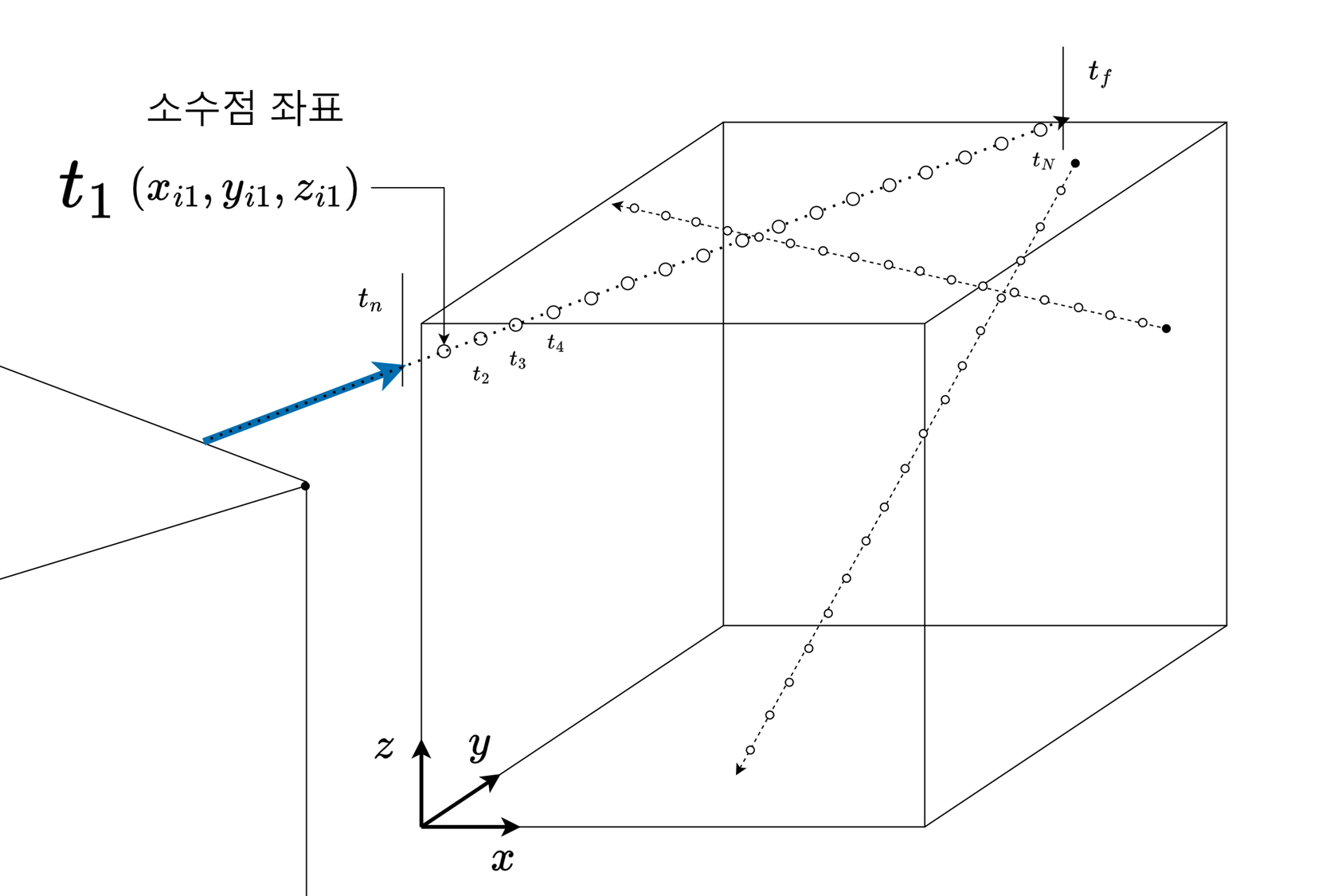
여러 방향의 Ray에 의해 모델링하려는 범주에서 Ray 선상에 따라 좌표들이 샘플링 되는 모습
이 샘플링 방식은 다양하며, 모델에서는 수식적으로 표현되어 있다.
해당 부분에 대에서는 추후 포스팅에서 다룬다.

모델을 복셀로 표기하여 정수값의 좌표를 학습하는 것으로 초기에는 오해를 했었다.
그러나 정수값 단위로 좌표가 샘플링 되지 않고 철저히 알고리즘에 따라 실수 값으로 샘플링이 된다.

논문의 그래프를 밑에 Ray 에 대한 그림 주석을 달았고, 이를 비교하여 보면 이산화 된 좌표값들을 연속-비선형 함수로 근사화 하였음을 보이고 있다.
